机器学习算法实践-随机森林
随机森林,指的是利用多棵树(即决策树)对样本进行训练并预测的一种多分类器。它是一种集成学习方法,是bagging算法的特化进阶版算法。故本文会先介绍集成学习以及其一个分支:bagging算法,再引出随机森林算法的基本思想。
0 随机森林主要学习内容
1) 集成学习思想:训练若干个弱学习器,然后通过一定的策略将其结合起来成为一个强学习器
2) Bagging算法:弱学习器之间没有依赖关系,可以并行生成,采用有放回的随机采样获取每个弱学习器的训练集。
3) 决策树算法:详细内容可见第一章决策树的讲解。
4) 随机森林算法:重点区分随机森林中的决策树与普通决策树的不同
1 集成学习
在介绍随机森林之前,我们需要先了解一下集成学习,因为随机森林就是集成学习思想下的产物,将许多棵决策树整合成森林,并合起来用来预测最终结果。
1.1 集成学习概述[2]
对于训练数据,我们通过训练若干个学习器,然后通过一定的策略将其结合起来成为一个强学习器,从而达到很好的学习效果。
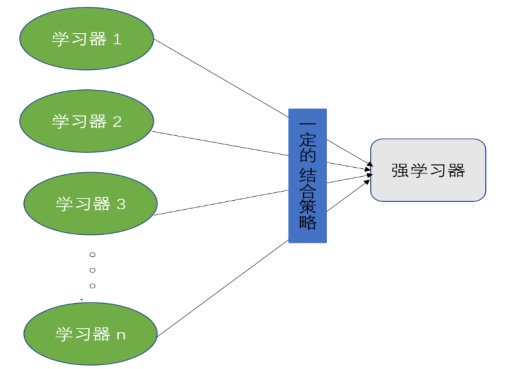
从图中可以发现,集成学习是由两个部分构成,一个是若干个学习器,这些学习器都是弱学习器,在有的框架中又称初级学习器。另一个是选择合适的结合策略。
1.1.1 学习器
学习器通俗点讲就是我们在机器学习中所学的算法,这些常用算法我已在0章构建机器学习框架时罗列出来了。
多个学习器的构成一般有两种选择方式。
第一种就是所有的个体学习器都是使用同一种算法,如:在一个集成学习中构建5个学习器,每个学习器使用的都是决策树算法,即5个决策树学习器。
第二种就是所有个体学习器使用的算法不全是一种类型,如:在一个集成学习中构建5个学习器,有两个学习器是使用决策树,一个使用朴素贝叶斯算法,一个使用支持向量机算法,还有一个是使用k近邻算法。
这两种方法中都存在多个分类器,它们各抒己见,故为了综合它们的意见,需通过某种合适的方法来最终确定强学习器。
目前,在集成学习中使用相同个体学习器的应用比较广泛。根据相同个体学习器之间是否存在依赖关系可以分为两类,一类是存在强依赖关系,个体学习器基本上需要串行生成,这样的代表算法是boosting算法,另一类是不存在强依赖关系,个体学习器可并行生成,其代表算法是bagging算法。


3)学习法
上面两种方法比较简单,但也容易导致学习误差较大,于是就有了学习法。对于学习法,代表方法是stacking。当使用stacking的结合策略时,我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集放到弱学习器中学习,学习出的结果作为特征输入,训练集的输出作为输出,再重新训练一个学习器来得到最终的结果。
Stacking原理[4]
假设我们有两个个体学习器,也称初级学习器model1,model2。
(1) 对初级学习器model1,利用训练集D进行训练,然后用训练好的model1预测训练集D和测试集T的标签列,结果为P1,T1。
(2) 对初级学习器model2,重复步骤(1),得到预测标签结果P2,T2。
(3) 将两个初级学习器的结果合并,得到次级学习器model3的训练集P3=(P1,P2)和测试集T3=(T1,T2)。也就是说,有多少个初级学习器,次级学习器的训练集和测试集就有多少列(特征)
用P3训练次学习器model3,并预测T3,得到最终的预测结果。
例[3]:

该图就是一个stacking学习法。以5折交叉验证为例,先解释一下,k折交叉验证的思想:将数据集A 分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集A随机分为k份,每次将其中一个份作为测试集,剩下k-1份作为训练集进行训练。


前面有讲到集成学习中,根据各学习器之间是否存在强依赖关系而划分两个流派,有强依赖性的是boosting算法派系,无则是bagging算法派系。我们今天要讲的随机森林就是建立在bagging算法之上的。
2 Bagging算法[1]
bagging算法的个体弱学习器的训练集是通过随机采样得到的,通过m次随机采样,我们就可以得到m个训练样本,重复这一行为n次,可得到n个训练样本集。对于这n个采样集,我们可以分别独立的训练出n个弱学习器,再对这n个弱学习器通过结合策略来得到强学习器。
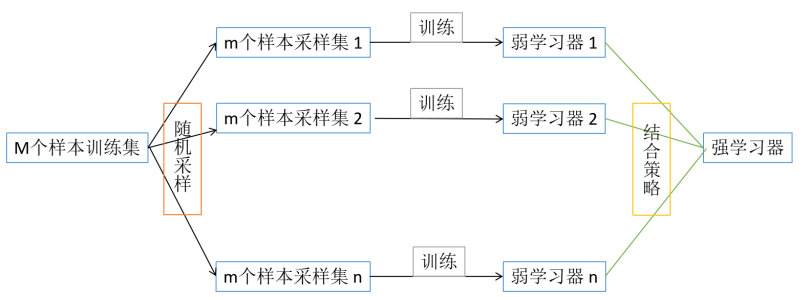
解释一下:这里的随机采样采用的是自助采样法,即对于M个样本集的原始训练集,我们每次先随机采集一个样本放入采样集中进行记录,之后将该样本放回原训练集中,也就是说,下次采样时该样本还有可能被采集到。就这样采集m次,最终可以得到m个样本作为一个采样集(对于bagging算法,一般会随机采集和训练样本一样个数的样本量,即M=m),重复n次,可得n个采样集。由于是随机采样,所以n个采样集也是大概率呈现不同的,可得到多个不同的弱学习器。


3 随机森林
随机森林是bagging的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在bagging的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离bagging的范畴。
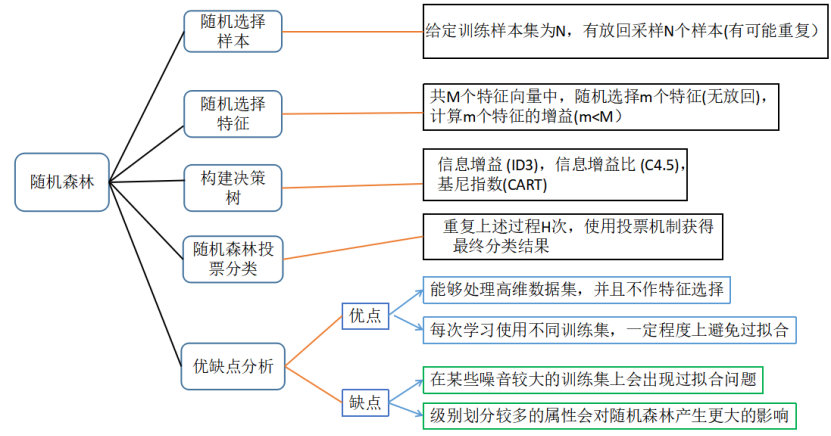
先要说明一下,随机森林的样本采样同bagging算法一样,有放回随机采样m个样本作为一个采样集,然后重复这一行为T次,可得T个采样集。第二,随机森林中所使用的弱学习器为决策树(使用了其他算法作为弱学习器的就不是随机森林),这里所用到的决策树与我们之前讲的决策树有了一些不同。之前所讲的决策树会在所有特征N中选择一个最优特征作为结点来划分左右子树。但在随机森林中,我们会先随机选择一部分样本特征n(这个数量应该小于N),再从这些特征中选择一个最优特征作为决策树的结点划分左右子树。这种做法也进一步增强了模型的泛化能力。
注:当n=N时,随机森林中的决策树和普通的决策树是一样的。当n越小时,模型约健壮,当对于训练集的拟合效果比较差,也就是说n越小,模型方差越小,但偏差会越大。故n的选择也需要慎重,一般会通过交叉验证调参来获得较为合适的n值。

4 随机森林的总结[1]
4.1 随机森林的优点
1)训练可以并行化,在大数据时代中训练大样本上速度具有较大的优势。
2)由于可以随机选择决策树结点的划分特征,故可在样本特征维度很高时依旧能高效训练模型。
3)训练后,可以输出各个特征对于输出的重要性。
4)采用随机采用,训练模型方差小,泛化能力强。
5)实现比较简单。
6)对缺失的部分特征不敏感。
4.2 随机森林的主要缺点:
1)在某些噪音比较大的样本集上,随机森林容易陷入过拟合。
2)对于取值划分较多的特征容易对随机森林的决策产生很大的影响,从而影响拟合的模型的效果。
5 随机森林的应用
1.乳房肿瘤类型的判断
2.Titanic中的应用
3.基因表达数据分析中的应用
4.量化选股中的应用
参考文献
[1] https://www.cnblogs.com/pinard/p/6156009.html
[2] https://www.cnblogs.com/pinard/p/6131423.html
[3] https://blog.csdn.net/wstcjf/article/details/77989963
[4] https://blog.csdn.net/pxhdky/article/details/85175406
[5] https://blog.csdn.net/kylinxu70/article/details/23065651
[6] https://blog.csdn.net/haiyu94/article/details/79400589
(部分文字、图片来自网络,如涉及侵权,请及时与我们联系,我们会在第一时间删除或处理侵权内容。电话:4006770986 负责人:张明)

- 近期消费类典型舆情热点梳理汇总分析
- 近期社会热点舆情分析
- 极端灾害中舆情监测的实战价值与路径
- 2026年7月网络舆情风险预警分析报告
- 从人设铺垫到信任危机:网络虚假测评乱象整治舆情复盘
- 极端天气下城市公共空间善意供给相关舆情分析
- 高考出分季招生谣言治理
- 鉴定一下近期网络热门词汇
- 2026年暑期文旅旺季景区服务类舆情风险预警
- 2025年度网络舆论生态新变化与舆情风险分析研报
- 2026 年 6 月外卖新规落地舆情跟踪报告
- 2026年5月网络热点舆情汇总分析报告
- 2026年6月网络舆情风险预警分析报告
- 鉴定一下网络热门词汇:碳水脸
- 剧本式舆情分析:以“盲道摆拍被撞”事件为例
- 应急舆情风险分析:安全谣言与虚假信息
- 近期教育相关热点话题分析
- 2026年4月网络热点舆情汇总分析报告
- GPT Image2等新一代图像生成工具规模化应用后的风险研判与治理建议
- 2026年五一文旅消费网民关注点分析
- 2026年五一假期舆情风险预警分析报告
- 2026年消费舆情分析报告:误导性商标乱象舆情观察
- 赛事经济:赛事文旅相关网络舆情传播分析
- 比水军更像真人,比真人更会执行:OpenClaw小龙虾类智能体时代,舆情工作应该注意什么
- 为什么随机刷到的视频的点赞数,首位数字三成是1? --谈本福特定律、社交网络推荐算法和对舆情工作这的启示
- 有效规范算法应用 营造清朗网络空间
- 社交网络内容分发算法对谣言类舆情传播的影响
- 机器学习算法实践-决策树
- 机器学习算法实践-随机森林
- 机器学习算法实践-感知机
- 机器学习算法实践-k近邻算法
- 机器学习算法实践-朴素贝叶斯算法
- 机器学习算法实践-神经网络
- 机器学习算法实践-Adaboost算法
- 机器学习算法实践-线性回归
- 机器学习算法-k均值聚类
- 深度学习-卷积神经网络
- 深度学习-循环神经网络RNN
- 自然场景文本识别