监视社交媒体:关于支撑信息战的社交媒体分析的报告3/5
第3章 支援信息战的社交媒体分析方法
在上一章中,为研究社交媒体分析应用于信息战的潜在利益,我们提出了一个基于IRC的框架。在本章中,我们进行一些更具体的描述:采用方法学的方法去检测公众对极端组织宣传的接受程度;确定文化或区域关注的热点以分析消息转发策略;解决其他信息战问题。本章并不专注于特定的技术或算法,有关这些特定技术或算法的讨论很快会变得过时。相反,我们探索使用一些有前景的方式,在一个熟悉的框架内解决常见的信息战挑战性问题。例如,类似Clauset-Newman Moore算法的社区检测算法,可能会被更优秀的算法所取代,但是识别和分析一个社交网络中的群体这个需求是一直会有的。
作为数据源的社交媒体的局限
本章中研究的概念和方法对国防部可能有巨大的潜在价值,对于信息战来说,社交媒体无疑是重要的数据来源。然而,对于社交媒体平台和分析工具的使用也有一些局限:
•社交媒体普及率在世界各地是不同的,这反映在某一既定任务区域中可用于分析的数据量(以及它们的适用性)。
•社交媒体数据不具有广泛的代表性。社交媒体的参与者都是自选择的,因此,他们共享的数据会自然而然地朝网络媒体参与者群体倾斜。
例如,对社交媒体中共享的照片集的自动图像分类结果数据进行分析,可以揭示什么样的人群想法子集是值得分享的。
社交媒体分析中的主要概念和方法
下面提到的若干分析方法并不详尽,但它们显示了所有可能的分析方法的大致范围,并说明了综合使用多个分析方法所产生的效益。大多数的方法使用文本分析(反映了社交媒体中基于文本的数据的丰富性),我们也介绍了包括网络、地理空间和图像分析方面的实例。
本章涉及的方法论概念主要包括以下内容:
•社交网络分析。社交网络分析(SNA),它包括社交结构的识别和可视化,涉及到心理学、人类学、数学中的图论等方面的知识。它涵盖了在海量的社交媒体数据集中自动检测社区的算法。
•公众分析。公众分析是公众说服分析的一部分:对有倡导权益的人的一种抽象,这些人使用共享的语言来解决一个常见的问题。美国步枪协会就是与倡导有关的组织的一个真实例子,然而使用相同语言且以私人持有武器合法化为共同目标的公众,则是一个更大的抽象。那些寻求限制武器私有化的反对派,同样比任何正式的游说组织要大。这类分析专注于那些关注某些问题并使用共同的论述来影响辩论的人。
•词法分析。文本分析方法起源于语料库语言学研究3。词法分析使用统计检测计算单词的频率、单词的距离及其它特性,以检测文本数据结构和模式。它最常用于通过显而易见的文本及单词联系,以经验推断一个文本集是在说什么。
注释3:语料库语言学是语言学的一个分支学科,其特征在于基于海量文本数据集(语料库)的实证研究。由于语料库语言学是基于机器的,它缺乏人工分析的上下文敏感性和精度,但人工分析不能达到其可扩展性和可靠性。
•立场分析。作为一种更复杂和更精细化的情感分析方法,立场分析重点检查单词和短语的频率(比如愤怒、悲哀、未来、过去、确定、不确定等)。它有益于回答有关态度、情感和价值的社会文化问题。
•地理定位和地理推理。是两种地理特定的方法,用于判定一条社交媒体消息的地理源点。地理定位使用GPS戳并且相当精确,但是用户常常关闭这项功能。地理推理可以基于元数据捕获大量的数据样本,用于推断发帖者的地理位置,其中一些方法具有相当高的精度水准。
•深度神经网络。深度神经网络(DNNs)通过将复杂的抽象任务分解简化为不同层次,使机器能够学习分类任务。例如,尽管人可能通过观看一张图片从整体上识别一辆坦克,但DNN图像分类器可以通过编程来区分不同的金属质感、胎面形状、主炮形状、低反射值,以及其它因素来描绘一辆“坦克”,并且具有一定的准确度。人类分析师可能需要花费一年的时间搜索成千上万的图片,以一个具有强大计算能力的、经过良好训练的DNN模型来代替,则只需要几天时间就能对同一组图像进行分类。
分析社交媒体数据的若干方法
尽管社交媒体数据越来越多地包括图像、声音和视频,文本数据仍然占主导地位。在下面的章节中,我们回顾各种社交媒体分析方法,尤其是文本数据,这些方法在解决信息战的问题时有非常实际的应用价值。表3-1总结了本章中介绍的以及应用范例中涉及到的几类分析方法。
网络描述:在社交媒体中发现极端主义网络
虽然本章主要侧重于分析方法,我们注意到描述性工作的价值,它可以为推理提供重要的启示。本节详细描述了表征极端分子网络的方法——具体而言,网络成员中那些积极参与支持活动的人4。该示例的目的是刻画谁是在推特上积极支持ISIL的人,但是这种方法也可以适用于其他网络组织或者其他为社交网络分析(SNA)提供数据的社交媒体平台。
注释4:各类不同的分析方法对于检测网络群体在社交媒体平台上的一般对话都是有用的。
表3-1一些支持信息战的社交媒体数据分析方法

在该示例方法中,现有的ISIL支持者被用于确定其他支持者。结果是一个相当大的数据集,在推特上有100万至135万的ISIL的积极支持者。识别网络成员是一个三步骤的过程,结合了可扩展的机器方法和有人监督的随机取样检查方法,以保证识别的精确性。
使用种子账户识别网络成员
分析过程的第一步是手动培育一个已知的在推持上活跃的极端分子成员的种子列表。即使对专家来说,这也是一个劳动密集型的工作过程(一个两人团队,通常需要数月时间)。在对推特活跃用户当中对极端组织有明确的积极支持倾向的帐户进行手工搜索时,研究人员发现了424个活跃的ISIL的支持者帐户——或者称为网络模型中的0级帐户。
第二步是从种子列表开始,使用匹配的网络连接来推断其他支持者。不像基于内容来识别关系的其他方法(参见下一节,“公众分析:在社交媒体上映射论证空间”),在这里,联系的方向很重要。设想一下一组推特用户评论一个受欢迎的电视节目的情景,参与者可能包括演员、制作人员、演播室代表、记者以及粉丝。如果我们已经分辨节目网络的全部成员——明星、编剧、导演等——我们就有可能通过对谈论该节目的用户进行研究,分析他们的联接方向,推断其他可能的用户:明星可能有很多很多的关注者(大部分是粉丝),这些人并不直接和节目有关,但是明星所关注的人则很有可能与节目有关。
因此,以极端分子网络为例,忽略那些关注0级种子成员的人,转而重点识别那些0级种子成员所关注的用户,则可能获得相关网络成员(1级)的更准确的图像。在这一例子中,过滤掉嫌疑的机器人和病毒帐户后,经过第一步分析之后得到的网络组织成员大约有43000人左右。但是,当然不是所有的被0级成员所关注的人都是ISIL的推特支持者,需要进一步剔除。
使用小圈子和网内聚焦提高网络成员辨识能力
第三步,鉴别谁是积极支持ISIL的网络用户的第三步,是要基于他们在推特上公开的同ISIL的联系、以及他们在网络小圈子和网内焦点的活跃程度,对他们进行排序。在网络分析中,这几个概念定义如下:
•圈子(Cliques)是一个网内的子结构,其中每个节点都连接到其他节点。设想一个大型的“新英格兰爱国者”的支持者网络,在该网络结构中,你可以发现很多小的“圈子”——在这种更小的组织中,每个人都会认识另外的任何一个人。这可能是在波士顿以邻居形成的紧密的朋友圈,或者虽然他们从没有互相见过面,但通过在线互动而相互非常了解对方。重要的是网络中圈子的度,这能够帮助鉴别网络中的成员关系。
•网内聚焦是指网内的联系多过网外联系(与组织外的用户交互)的发展趋势。以足球为例,“新英格兰爱国者”的非正式的粉丝都会有一些网内的联系,但是如果某个人的网络联接比率开始倾斜——如果一个用户主要是指向网内——这表示会员身份的增强。
对43000第1级别的帐户进行分类,在识别支持者时,结合使用多种度量比使用单一度量有效得多。在分析员抽查时,这种方法对数据集中前20000个帐户的精度非常高,但是当超过30000个帐户时,精度会快速地下降到48%。所以,在这个例子中,研究人员能够描述一个包含20000人的活跃的ISIL支持者大型网络的人口统计资料和活动,并能高度保证数据集是精准的5。
注释5:在这种情况下,更大规模的n-步分析是可能的——例如,在1级用户之外采用一个附加步骤,检查他们使用可扩展方法(如机器学习)的情况,从活跃的支持者中筛选更大的网络。
公众分析:社交媒体话题空间的可视化
除了描述像ISIL极端组织的社交网络,SNA(社交网络分析)和词法分析的组合使用还可以用来表征ISIL在社交媒体上的意识形态斗争6。该方法使用社区检测算法来识别所涉及的群体,并使用词法分析来表征这些社区。这种方法不仅能直观的呈现谁在跟谁说话,而且能知道他们在说(关心)什么。其结果就是围绕ISIL的讨论空间的社交媒体图。图3-1显示了通过研究发现的顶级集合群落图,以及它们之间相互联接的密度和方向。
注释6:这项研究的规模说明了为什么计算机分析对信息战,以及从更广的意义上说对社交媒体数据搜集是至关重要的:源于771371个推特用户帐户的2300万条微博信息。
图3-1经过两步创建。社区检测揭示了网络结构,基于每一社区内容的词法分析描述了用户组织的特征——特别是从人口统计学的角度来看他们是谁,以及他们关心什么。
图3-1 推特中支持和反对ISIL的集合群落

注:箭头的粗细表示集合群落之间的连接强度相较于社区规模的高低。节点大小代表社区的大小。红色节点表示逊尼派集合群落的成员。由于资源的限制,不是所有的社区都能用词法分析检测到;没检测到的社区没有给出标签。
MC:集合群落;GCC:海湾合作委员会(Gulf Cooperation Council);Shia=Shiah:什叶(派);Mujahideen:圣战(者);ISIL:伊拉克和黎凡特伊斯兰国(Islamic State of Iraq and the Levant);ISIS:伊拉克和大叙利亚伊斯兰国(Islamic State of Iraq and al Shams)。
社区检测
这种方法的第一步是搜集关于某一个问题或某一利益团体的社交媒体数据——在本例中,有超过2300万的推特帖子来自于77万多的ISIL支持者和反对者。领域专家对搜索ISIL可能的支持者或反对者提出了相关的搜索词语建议:搜索短语和标签变体都包括阿拉伯语的“达伊沙(Daesh,伊斯兰国)”和“伊斯兰哈里发(Islamic Caliphate)”。
因此领域专家的直觉就是通过机器阅读实现机器验证——将词法分析技术应用于收集的数据,然后确认对使用“达伊沙”和使用“伊斯兰哈里发”的不同网络社区的区分是否准确地分辨出反对者和支持者(下一节详细描述)。在这种情况下,主要的测试都表明,事实上使用“达伊沙”的社区同样会使用贬义词称呼ISIL(如“哈里哲派(Kharijites,出走派)”,一个对主流伊斯兰教的古老反对派的称谓),同时使用尊敬的词语称呼阿拉伯国家和西方世界(如“国际联盟”)7。使用“哈里发”的网络社区使用敬语称呼ISIL(如“伊斯兰国的狮子”),使用贬损的称谓指代阿拉伯国家(如称呼阿拉伯国家“叛教者(apostates)”,称呼西方国家“十字军(crusaders)”等)。这一分析过程是一类非常有效的检验措施,意味着这些搜索词可以作为非常有用的判别参数:一个词语对另一个词语在使用方面具有压倒优势,据此能够有效地分辨一个用户对ISIL的态度。
注释7:关键测试涉及某些词语的发现频率的测试和统计重要性的检测。预期的词频可以使用通用标准检测(例如有代表性的单语种的语料库,如开源阿拉伯语语料库),或者使用特殊标准检测(例如,针对一般社交媒体交流,每天进行广泛的搜集)。有关这些技术的其他背景,参见Scott(2001)。
一旦将社区检测算法应用于社交媒体数据,这种词法验证将为下一步的重要过程创造条件。推特数据(或者其他相似平台的数据,如新浪微博)对社交媒体分析工作来说是能够不断修正和完善的,因为像回帖、引用和转发等操作都标记了网络交互行为。通过描述和分析这些网络交互,一种网络社区检测算法能够快速地对用户进行分组,将其归并到互联的结构中,但是不能对他们命名,也不能描述他们的特征。该算法只能简单地发现社区1、社区2,等等。但是“达伊沙”和“哈里发”等判决词能很快标记出每个社区是支持还是反对ISIL的,并将支持者归并到同一组。
描述社区特征
虽然社交网络分析用于分析网络社区以及它们之间的交互关系——“达伊沙”和“哈里发”等判决词用于显示“支持”或“反对”的立场——从信息战的角度看,网络社区关系图仍是空白,没有标识。不理解对于ISIL持不同立场的各方的特点及关心的问题,就没有可行的途径去影响它们彼此之间的对话协商。
一个突出的问题是,相对于人的分析能力,推特的微博数据池过于庞大。在可扩展性之外,人类的可靠性和偏见等特征仍是分析工作的一个问题。可扩展的、可靠地表征这些社区需要对检测到的社区的推特内容进行机器分析。一种解决方案是源于语料库语言学的基于机器的分析方法(词法分析)。词法分析取决于字频或字距的统计测试,该方法能显示文本数据的结构。在本例中,对文本数据使用了两种方法:关键字测试和组合测试。关键字识别从统计角度描述了一个文本数据集中词语,并展示出所收集的文本数据的主要内容。因为关键字加权由它们的统计异常情况决定,所以关键词测试在弱信号检测时具有更高的判决能力。与关键词不同,搭配词在统计上非常显眼,因为它们表示了共同出现的词语,这些组合词往往就勾勒出了文本的大意8。
注释8:比如,地名(“纽约”),人名(“奥巴马总统”),以及抽象概念(“禁枪”)等。
识别公众和可能的宣传策略
对于统计频率很高的关键词及强相关的组合词的自动识别,使得被检测的网络社区表征为一个公众:使用共享语言讨论一个公共的问题,并持拥护立场的人们的抽象。举一个美国大众都熟悉的例子,设想一个禁枪的话题。一方面,美国全国步枪协会是一个持拥护立场的现实世界的组织实例,但是使用共享语言且致力于将私人拥有武器合法化这一共同目标的公众则是一个更大的抽象。寻求限制武器私有化的持反对立场的公众也要比任何官方游说组织要大:这是一个关心某个问题并使用共同的公开信息来影响辩论的公众组织。
回到我们最初在推特上识别ISIL支持者的例子,社交网络分析显示有4个大的集合群落,对它们使用词法分析可以定性为元公众。一个社区可以通过关键词及其他组合词来联合标注,如沙特的关注(包括沙特民族主义),对ISIL的世俗或宗教的贬义用语(恐怖主义分子,犯罪和罪孽,逐出教会,混乱等),以及对宗教内涵的褒义词(赞美,荣誉,真理,爱等)。这里的一个关键环节是,一个使用词法分析软件的分析师,能够替代一整个阅读数百万推特帖子的分析师团队,他能够识别识别上百个统计上异常的词语和短语来表征一个社区为公众社区。以下是本例中发现的4个大型的网络公共社区:
•逊尼派ISIL对手(一些支持者)
•什叶派ISIL对手
•ISIL支持者
•叙利亚圣战者组织(对ISIL怀有多种复杂态度)。
社交网络分析和词法分析一起使用能够支持更细粒度的分析,为面向影响特定公众群体的貌似真实的消息传播提供经验基础。表3-2显示了使用“逊尼元公众号”识别出来的个体公众社区(特别是以国籍身份和以所关注话题组织起来的社区),以及每个社区的关注点和兴趣话题。
每个公共社区的话题和关注点为可能真实的消息传送策略及有针对性的社区成员宣传策略提供了经验基础。在这里,我们重点强调该方法的可扩展性和诱导价值。这是一个分析师数天的工作量,而不是一个团队花费数月去阅读成千上万条的推特贴子。而且由于分析工作完全依赖于用户所产生的社交媒体数据,反映美国文化假设和优先的要旨难以有植入的机会,因此更加客观公正,分析工作可以在一个合适的粒度层面上来完成。
表3-2 推特中逊尼派公众对ISIL的反对/支持分析

来源:兰德公司针对推特2014年7月至2015年5月数据的分析。
共鸣分析:基于社交媒体跟踪信息扩散
本节详细介绍针对一个网络集团在某一合适的地理粒度上对消息随时间推移的传播接受情况的跟踪方法。这里提及的概念验证研究主要用于跟踪2014年埃及ISIL和穆斯林兄弟会成员中世界观相关的信息传播和接受情况。该方法有巨大的潜力来衡量有效性,包括友好消息传输方面的工作。
该方法的基础是语言和世界观之间不可分割的关系,语言反映了世界观,反之,世界观也通过语言塑造。在争议性议题的语言表达上,我们可以很清楚地看到这种关系。在论述某一特定话题过程中一直使用的词汇不是简单地反映意识形态;它们的使用同样有助于通过包装世界性问题和事件来促进意识形态的流通和传播。因为如果我们能够对公众的讨论在数量方面建模,我们就能够跟踪通过语言表达的世界观的接受情况。
建立语言模型
该方法的第一步是建立一个面向公众谈话的加权语言模型。在这个例子中,它是一个极端组织,但它可能只是一条战斗命令和这条命令的区域传播。在这个概念验证例子中,分析师从ISIL和穆斯林兄弟会(每个组织约30000词汇)的公开谈话中搜集数据,然后使用关键词和词语组合对数据集进行测试。这样每一个集团就会产生基于大约100个左右的统计关键词和20个左右的双词组合的语言模型。为了帮助对我们所指的加权语言模型进行概念化描述,表3-3给出了一些关键词示例、对数相似度以及每个单词的英语翻译。
在这个特殊的测试中,对数相似度大于11表示很重要。在表3-3中,某些词如伊拉克(Iraq)或沙姆(Sham)的两位数的值表示它们被大量使用,并且能够被检测到,而数百的对数相似度(如拉菲达(Rafidhi))则是非常强的语义信号,表示整篇文本主要描述的内容。超过1000的分数显示了高度专业化的谈话,是一个标志性的信号:在努力理解ISIL交流信息的时候,从定性分析的角度看,像萨法维(Safavid)这样的词语可能不是一个顶级话题,但是从检测弱信号(如效果和影响)的经验角度看,这样一个出乎意料的高频词应该是一个强有力的分析抓手。
表3-3 ISIL和穆斯林兄弟会关键词示例,对数相似度排序

注:对于对数相似度,临界值是10.83(0.01%,p<0.001)。在这个例子中,最小频率是20。为了解释本表中的对数似然(LL)值,我们设想LL>11表示统计重要,11和1000之间表示极高级别的关键程度(高点位的谈话),分值大于1000表示指向极端专业化谈话的关键词。
有了信号模型的帮助——针对萨法维集团(Safafist groups)谈话信息的定量加权模型,下一步是检测模型和公众谈话内容的一致程度:这些集团在传播他们的信息方面是得势还是失势。
社交媒体谈话和极端分子信息交流的区域匹配
给定一个极端组织的谈话的语言模型,有可能看到普通人群中的社交媒体用户和谈话内容的匹配程度——定量匹配出一个网络群体的话语在整个话语市场的共享程度。设想一下在私人拥有枪支这个问题上对美国东北部的社交媒体进行监控。
每一季度,针对以下词语的使用都在不断增加,例如:大规模射杀、无谓杀戮、无辜等,而以下词语则使用较少,如:负责任的所有权、第2修正案权利、犯罪等字眼。这强有力的表明了有一方在公众舆论中正得势,至少能从中知道这个讨论是关于枪支危险的,而不是关于公民自由的9。一般的分析过程如下:
注释9:我们注意到这种方法不能让我们回答为什么会发生这种改变,只能让我们看到发生了改变。如果要了解其中的因果关系则需要其他方法。
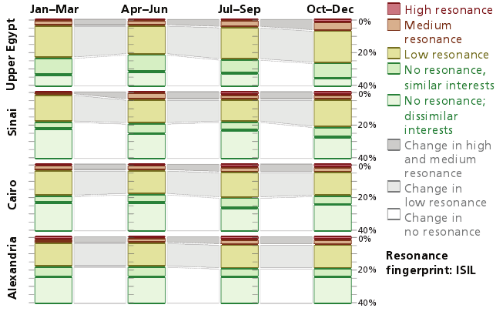
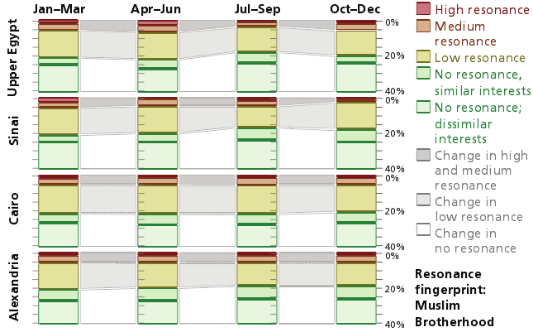
•从一个有意义的地理人口中搜集社交媒体数据。在我们的主要案例中,数据源主要来自2014年埃及四个区域的推特数据:西奈、亚历山大及滨海地区、上埃及、开罗和尼罗河三角洲。在该例中,在对用户所在区域进行地理推断时既使用了城市名称也使用了省的名称,这使得数据量翻了一番,但是,当回查地理标签数据时,得到的是80%准确度的更低可信度的边界。
•根据对语言模型的匹配的统计数据,对推特用户简讯进行打分。每一位推特用户的简讯都可以根据其与语言模型的匹配程度进行打分(如ISIL和穆斯林兄弟会):
–给定了用户推文中出现词语的总数,以及所有推文中的关键词和搭配词的频率/平均值之后,还需要针对每一用户,将其所有推文中全部关键词和搭配词出现的相似度进行统计求和,并计算期望值。
–结果值是对匹配有多可能是随机的匹配的判据:
◦高:意味着一个帐户使用了比随机概率期望值高出500%的模型语言(ISIL和穆斯林兄弟会)。
◦中:意味着一个帐户使用了比随机概率期望值高出300%的模型语言,但是低于500%。
◦低:意味着一个帐户使用了比随机概率期望值高出50%的模型语言,但是低于300%。
◦无:意味着一个帐户的语言反映了随机概率的水平。
•描绘出随时间变化的图形。在用户层量化确定的高、中、低、无级别的匹配可以在地域级进行汇总:一一种衡量一个网络群体消息传播的扩散程度等级的方法。经过逐个季度的比较,既能测量消息随时间传播的有效程度,也可以对各种传播方式进行优先性排序。
这个例子中,在2014年度,ISIL和穆斯林兄弟会在亚历山大和开罗地区保持了很低的匹配度——这对美国来说是一个好消息。但是在西奈和上埃及地区,ISIL拥有高度和中度的共鸣匹配度,相比这下,穆兄会则失去了不少的人气。本质意义上,ISIL在这两个地区获得了市场份额——对美国来说是坏消息,图3-2和图3-3显示了市场份额的这个变化。
立场分析:检测社交媒体中信息传送策略
图3-2 埃及ISIL的语音共鸣,2014
为什么某些极端分子的消息传送策略能够成功,而其他一些极端分子会失败?美国国防部能够成功分析其成功的原因,获取其中的关键技术并指导信息战吗?是否能够明白为什么某些敌方的消息传送方式具有特别的功效,并学习如何使自己的消息传播更有效,而不管是使用什么媒体来传播?立场分析着眼于社交媒体消息传送,揭露消息传播中的语言细节,以便更好地理解它是如何工作的。这类似于情感分析,但它更详细和复杂。本章中先前所讨论的方法中使用词法分析(在词汇的数量和频率层面进行统计检验),这个方法在词语种类的层面使用数量和频率的统计检测方法。关于词语种类,我们所指的意思可举例说明如下:如未来和过去、情感(例如愤怒、悲哀、害怕、主动等)、确定性、价值、社交关系等。将多种词语整合到若干个主题中,能够实现某个目标,并能揭示某些可检测的信号。比如,当谈及未来和希望的时候,这会是一种激励人的策略,和谈及过去和历史错误的选项具有显著的区别。经过对词类的频率、分布和协方差等的统计检测,基于计算机的分析方法能够在细节层面检测到相关主题和消息传送方式。
图3-3 埃及穆斯林兄弟会的语音共鸣,2014
作为例证,假设一个新上任的人力主管将一份备忘录发送给中心的每一位正式职员。该备忘录收到了很差的效果:备忘录的本意是激励员工共同努力弥合分歧,但是相反,它起到了反作用,使员工对这位新的主管产生了极大的愤怒。当员工被问及的时候,都会将矛头指向那份备忘录——它看起来疏远且傲慢。为什么显得“傲慢”?仔细检查文中的用词就会发现,备忘录中充斥着第一人称和第二人称单数名词,但通篇缺少第一人称复数名词:当提及解决方案时总是说“我”,当谈到问题时总是说“你”,谈任何事情从来不用“我们”。尽管人力主管没有意识到这个问题,久而久之,这种方式的遣词也会在读者中产生较强的对立情绪。对于像单一记录这样的,由话语分析师经手的分析会非常高效和有用。但是对于海量的社交媒体数据,计算机分析还是必要的。
发现ISIL社交媒体交流中的潜在因素
为了测试这种方法,我们对从四个极端组织搜集的社交媒体数据集进行了演示分析:伊拉克和黎凡特伊斯兰国(ISIL)、胜利阵线(al-Nusrah Front)、阿拉伯半岛的基地组织(AQAP)和圣战组织(Ansar al-Sharia)10。我们使用经过翻译了的这些组织在2014年第四季度的三个月的社交媒体数据11。然后,我们用最先进的(截至2015年)的情感分析软件对每个语料库词语种类频率进行处理,同时对此进行频率、分布和协方差的统计测试,以检测不同组织之间差别,和每个组织内部交流用语中不同结构特征间的差别。
注释10:我们注意到:这个分析方法是初步的,是作为一个方法的概念验证实施的。该数据池相对较小(极端组织三个月的社交媒体数据输出),而且分析使用了翻译文字。尽管有初步的证据表明在这个分析过程中使用的翻译软件运作良好,我们强烈质疑分析结果的准确性。本节的目标是展示方法,不是使用该方法探索产生的某些特定发现。
注释11:这个分析方法使用的数据是从SITE情报组织商业化订阅的,该组织是一个从事伊斯兰圣战分子监控和分析的实体组织。
为了演示说明,我们详细描述这个分析过程中的一个发现:当我们使用探索性因子分析法寻找潜在的主题结构时,我们发现ISIL和胜利阵线有3个因子(说服性主题、个人宣誓、共同关注的社会焦点问题),而基地组织的社交媒体数据有一个因子(技术性问题的窍门指导)。探索性因子分析法将一组变量间的相关性看作一个单一的潜在因子,通过数据集中的协方差,检测其中的潜在性因子。在文本分析中,一篇普通的“当你变老,它会更好”的演讲可能看起来更像面向未来的积极谈话和安慰性语言的交织。下面的例子勾勒了导致基地组织(AQAP)的公共社交媒体语言显著区别于胜利阵线(al-Nusrah)和ISIL的几个因子12。
注释12:圣战组织(Ansar Al-Sharia)没有能探测到的因子——该组织的讲话通常前后不一致,缺乏重复连贯的战略。
阿拉伯半岛基地组织的主题策略
基地组织(AQAP)显著的判别因子是“信息性”(informational):共享技术、概念性知识和报告重要事件。这主要源于从网络空间作战到规避热探测的技术指导。例如:
这一幕显示了一群圣战分子在一条狭窄的通道里试图躲避航空照像机的画面,但是热成像记录仪清晰地显示了他们的身体,特别是飞机在低空的位置时。因此,看来解决方案是对航空照像机隐藏身体的热能。美国人将这项技术叫做热绝缘。热绝缘技术在我们很多的日常工具中都有应用,比如热水瓶。热水瓶在内部维持水的温度不变,因为它里面的绝缘材料能阻止热量向外面逃逸。而且,电冰箱,或者也称之为冷藏柜,保温茶壶,或者恒温的集装箱等,都使用了热绝缘的技术。
同样的模式在信息报告中也可以见到:
上周四,在南也门阿比扬省,一名胡塞武装分子死于南也门阿比扬省圣战组织的狙击。上周四的上午10时,阿比扬省的圣战组织新闻记者报道了该事件,伊斯兰教圣战者组织的一名成员狙击了驻扎在阿比扬省al-Mahfad地区的第39装甲旅的一名士兵。
ISIL和胜利阵线(Al-Nusrah)的主题策略
ISIL和胜利阵线(al-Nusrah)有3个相同的潜在因子。与基地组织共享信息的技术方法不同,ISIL和胜利阵线(al-Nusrah)在社会文化领域劝导他们的听众时使用目的性很强的信息策略。
超越:前景更美好
胜利阵线(以及ISIL)使用类似的扩张战略。也许与直觉相反,他们的主导宣传策略并不包括负面的或仇恨的言论,而是专注于正面价值和宣传的热烈的、面向未来的谈话13。例如:
注释13:与之相反,圣战组织和ISIL不使用这种策略。
谁想支持真主安拉、伟大和全能的神,就让他宣誓效忠这个哈里发。谁若希望真主的伊斯兰教,伟大和全能的伊斯兰教得到普世运用,就让他宣誓效忠这个哈里发。真主安拉、伟大和全能的神,现在就能分辨诚实和谎言。
个人请求和宣誓
虽然ISIL的特征是不使用主语“我”讲话,但是它和胜利阵线(aL-Nusrah)在表达人际间的请求意愿时也会使用“我”说话,例如像这样一种有说服力的证词14:
注释14:这一策略从基地组织社交媒体谈话中丢失了。
我对我提到的事实作证。我会强调我的眼睛所看到的,我的耳朵听到的,我的心感知到的,我会告诉你我所学到的。第十:我问你,以真主安拉的名义,没有上帝,只有他,把这个谈话转达给族长和沙姆(叙利亚)及其他地区的领导人。
一条统一阵线
在这两个组织的交流谈话中另一个重要的潜在因子是社会承诺和包容性的“我们/我们的”谈话的组合。这些演讲经常是重复性的(在阿拉伯语境中是真诚的标志),而且是非常依赖于宣誓效忠或忠诚的理念:
以真主安拉的名义,最光荣的、最仁慈的伊斯兰国,祈福真主阿布·贝克尔·巴格达迪,我们都誓言效忠于他,我们国家的埃米尔是胜利!伊斯兰国家,祈福真主阿布·巴克尔·巴格达迪,我们都誓言效忠于他,国家的埃米尔,我们的国家,是胜利!他们正在争取胜利!他们使用迫击炮和机关枪来迫使他们所有人都下跪。我们的国家是胜利!伊斯兰国家,祈福真主阿布·巴克尔·巴格达迪,我们都发誓效忠于他,国家的埃米尔,我们的国家是胜利!穆斯林,你准备好了吗?在经历了数百年的苦难之后你将获得自由。我们的国家是胜利!
我们从这一概念验证分析中得到的启示是:基于计算机来分析海量社交媒体数据能够为信息战谍报提供关于敌方信息交流方面的信息。在这种情况下,分辨出敌方采用的扩张或主题性策略是有力的一个步骤,它能够为消息传送的反制提供支持。
自动图像分析:以众包方式理解信息环境
该方法结合使用数据源地理信息和软件来进行图像分类和地图绘制,从而自动化的对海量社交媒体数据集中的图片分类和映射。最后,这有助于信息战指挥员搞清楚当地民众什么想法最值得分享(比如,卡车照片、军服、模因、卡通等),以及他们在什么地域分享信息:人们希望在特定的地点基于社交媒体分享什么样的直观的信息?而本章介绍的其他方法是试图解决文本流问题——海量的文本数据超过了人的阅读和分析能力——该方法为图像数据提供同样的解决方案,我们期望的这一数据类型只有随着全球范围移动设备的普及和网络容量的增长才能在数量上持续增加。我们认为该方法具有巨大潜力,主要基于以下理由:
•它主要面向远程数据采集,成本低,不会给其他资产带来风险。
•它开发了一条额外的数据流,该数据流随着社交媒体普及的增长而增长。
•它解放了专家进行人工分析的时间和精力。
•影像能够包涵丰富的文化信息,并且可能在识字率很低的区域具有特别宝贵的价值。
•这是一种众包的方式,对信息环境非常重要:它将影像置于那些当地民众认为值得分享的地方。
我们注意到,这是个区分信息战和情报工作的很好的例子。该方法能作为宣传作战的一部分来使用(当地民众最关心的文化和政治问题是什么?),但它能非常简单的用于搜集战场情报(我们在哪里能看到更多的用于分享的坦克、卡车、武器和军服的照片?)。将其区分为信息战行动的并不是方法,而是被问的问题和意图。
第1步:搜集特定地域的社交媒体资料
该方法的第一步是通过地理标记或地理推理15搜集本地的社交媒体数据。两种选择各有优点:
注释15:我们注意到移动终端在各个国家有很大的不同,地理标记和地理推理所用的数据量也会不同。因此,该方法的可用性在世界不同的地方也会有所不同。
•仅使用地理标记的数据能得到地理位置的较高准确度和细粒度。我们可以确切地知道社交媒体数据从哪里来,并在地图上将该位置标记为可能的分析部分(例如,城市或社区)。然而,由于大多数社交媒体数据都没有地理标记,这可能限制了用于分析的社交媒体数据的数量。而且由于游客往往会在移动设备上打开地理定位功能,这也可能会导致他们的图片使样本产生偏差。
•地理推理(例如,在用户的位置字段使用城市和省名)可以以较高水准的地理精度来捕获更多的数据。然而,它具有有限的粒度。在前面所述的在埃及社交媒体数据上跟踪信息扩散的例子中,80%的准确率只是在国家区域的水平上。
基于这样一组社交媒体数据,图像的URL可以剥离出来,附带有位置元数据的图像数据可以搜集下来,留下一堆海量的未分类的当地民众认为值得分享的图像数据。下一步是使用计算工具对这些图像进行排序和分类。
第2步:自动图像分类
下一步是使用图像分类软件对图像数据集进行分类。在写这篇文章的时候,深度神经网络(DNNs)是一种很有前途的方法,它将图像分成若干个抽象的层次,附带两个说明:
•处理能力。不像前面讨论的文本分析方法,图像分类是一类需要大量计算的任务,如果要使图像分类计算可行,就需要并行计算阵列(相对于单个桌面系统)的支持。在我们的例子中,搜集2周2015年推特和脸书中非洲范围的带有地理标签的共享图像,会得到283000幅图像。这需要大约三天时间的并行计算来处理。
•分类准确性。在图像分类的精确度和粒度之间存在一个平衡问题。在低层次的粒度上(例如“车辆”),目前的技术是非常准确的。但是在更精细的粒度级别(例如,“坦克”和“卡车”),准确性会降低。
第3步:绘制图像
在这个过程的最后一步是使用绘图软件绘制这些图像,可视化展示哪些组织在分享信息。而且由于这些数据有时间戳,我们也可以看到一段时间内的变化。为了演示这种方法如何支持信息战,可以考虑图像数据怎样指向关联的社会文化和政治问题及其内涵。在本节讨论的分析方法中,分类器发现了许多“漫画书”,最后发现是政治漫画16。这类图像和其他类别的图像可能会在帮助了解本地信息环境、当地民众选择共享什么内容、以及从哪里共享这些图像等方面有重要价值。
注释16:这突出显示了图像分类软件当前的一些局限。虽然漫画书和政治卡通书对人来说是两类不同的体裁,但它们却有相似的视觉特征。机器在进行图像分类时,使用不同的特征参数会有不同的开销和限制。
图3-4是使用深度神经网络(DNN)工具显示自动检测图像的屏幕截图,根据目标类别(政治漫画、建筑和车辆)和地理定位形成的图像共享地图。
能够直观地看到在什么地方、以及多大密度上人群关注的某个社会问题正在被“讨论”,是一种高效的方法来理解和发现信息环境中的动态变化。
图3-4 基于类型和地理位置的图像共享

原文链接: ![]() https://www.rand.org/pubs/research_reports/RR1742.html 翻译人员:刘江宁 郭长国 王晓斌
https://www.rand.org/pubs/research_reports/RR1742.html 翻译人员:刘江宁 郭长国 王晓斌
(部分文字、图片来自网络,如涉及侵权,请及时与我们联系,我们会在第一时间删除或处理侵权内容。电话:4006770986 负责人:张明)
- 近期消费类典型舆情热点梳理汇总分析
- 近期社会热点舆情分析
- 极端灾害中舆情监测的实战价值与路径
- 2026年7月网络舆情风险预警分析报告
- 从人设铺垫到信任危机:网络虚假测评乱象整治舆情复盘
- 极端天气下城市公共空间善意供给相关舆情分析
- 高考出分季招生谣言治理
- 鉴定一下近期网络热门词汇
- 2026年暑期文旅旺季景区服务类舆情风险预警
- 2025年度网络舆论生态新变化与舆情风险分析研报
- 2026 年 6 月外卖新规落地舆情跟踪报告
- 2026年5月网络热点舆情汇总分析报告
- 2026年6月网络舆情风险预警分析报告
- 鉴定一下网络热门词汇:碳水脸
- 剧本式舆情分析:以“盲道摆拍被撞”事件为例
- 应急舆情风险分析:安全谣言与虚假信息
- 近期教育相关热点话题分析
- 2026年4月网络热点舆情汇总分析报告
- GPT Image2等新一代图像生成工具规模化应用后的风险研判与治理建议
- 2026年五一文旅消费网民关注点分析
- 2026年五一假期舆情风险预警分析报告
- 2026年消费舆情分析报告:误导性商标乱象舆情观察
- 赛事经济:赛事文旅相关网络舆情传播分析
- 比水军更像真人,比真人更会执行:OpenClaw小龙虾类智能体时代,舆情工作应该注意什么